search engine optimization The LSG Manner: Cognitive Bias and False Precision in our SERP Psychological Mannequin
THAN THAT’S A MÜDCHEN!
In another life I was an academic random internet person, take care of it and move on.
So a couple of members of the team pushed me to document the Local SEO Guide’s SEO approach, and over the past few weeks an internal topic has come up that I think is a great example. I think the mental model we have for approaching SERPs and rankings is broken. In particular, it leads people to misunderstand how to approach SEO as a discipline, and it is all our own fault that the urge to make everything easy to understand and not complex. Complex things are complex, it’s fine. Just to be upfront, I’m not going to offer you any new heuristics in the context of this article, I’m just here Raise problems.
background
We need to build some conceptual foundations before we can tear them down.
First of all, it is important to understand two important concepts for this post:
Wrong precision: Using implausibly precise statistics to give the appearance of truth and certainty, or using a negligible difference in data to draw incorrect conclusions.
Cognitive bias: A systematic mistake of reasoning that occurs when people process and interpret information in the world around them and influence the decisions and judgments they make.
On our mental model of SERPs; I think it’s pretty hard to say that most people in SEO have a heuristic of SERPs based on these 3 things:
- Results are sorted by position (1-10)
- Result is increased by units of 1. elevated
- Results scale the same (1 and 2 are the same distance as 3 and 4, 4 is 3 units from position 1, etc.)
This is so totally and completely wrong in all points:
- The results are sorted by game into an information retrieval system (e.g. best game and various matches, etc.). In theory there are many different “best answers” in the 10 blue links. Best news site, best commercial site, best recipe, etc.
- The results are sorted according to how “appropriately” the web document answers the query. Not even close to a 1-10 linear ranking system. Below is a screenshot of the Knowledge Base Search API returning matches for “Tacos” with the scores of the second and third results highlighted:
If you want to dive deeper, Dr. Ricardo Baeza-Yates here in his in 2020 RecSys keynote on “Bias in search and recommendation systems”. - This follows logically from the previous point. From the screenshot of the Knowledge Base search results for “Tacos”, we can see that the distance between the search results is not really 1. The distance between position “2” and position “3”, which is highlighted in the screenshot above, is 64. This is to be REALLY important later.
Additional important knowledge
The internet and keywords are a long-tail distribution model. Here is a background article on how information retrieval professionals think about how to approach this in recommendation systems.

Long-tail distribution diagram
~ 18% of daily keyword searches are never-before-seen keyword searches.
Many SERPs cannot be clearly distinguished. For example, “cake“Has local, information, bakery, and e-commerce sites that provide” matching “results for versions of” pie “at the same time in the same SERP.
Effects
So I started looking at all of this about five years ago when I was working with statisticians on our quantitative research on local search ranking factors, and it has a lot of implications for how SERP results are interpreted. The best example is rank tracking.
It is assumed how much closer position 5 is to position 1 than position 11, but this is completely and completely obscured by the visual layer of a SERP. As I illustrate with the Google Knowledge Base API Search, machines compare terms / documents based on their own criteria that are explicitly not on a scale of 1 to 10. With that in mind, knowing that large systems like search are long-tailed, it means that many low-scoring “bad” results are still the “best” match for a query.
In these cases of the 18% of daily searches that are new instances, each search result could be very similar in ranking at position 1, separated by small differences. This means that for many inquiries it might be as easy to move from position 7 to position 1 as it is for them to move from position 12 to 1.
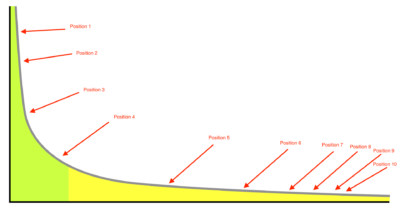
In the example above, to say that positions 7 to 10 are meaningfully different from each other is as if positions 1 and 2 were meaningfully different from each other in this example. It uses negligible difference in data to make wrong conclusions, which is the textbook definition of wrong precision.
To take it even further, the majority of the results on page 1 could be mediocre results for the query as it is new and search engines have no idea how to rank it based on their systems that use user behavior etc. to put things in order. Since this is a new query for them, many parts of their system cannot operate with the same level of accuracy as a term like “tacos” would. This means that the distribution between the positions on a SERP could be even more negligible.
Dan, how do you know the distribution is like this?!?!?!?!
Random internet stranger, please keep it up. None of us know how the ranking of items in a SERP is distributed, not even googlers. All hypotheses about how Google’s search results are displayed for orders cannot be proven to be untrue (falsified), e.g. B. You cannot do any of this scientifically. That is literally my point.
Back to “Tacos“; With such high-volume queries, the best results Google could deliver are likely to be incredibly good answers (depending on the system) and hardly differentiated in terms of the various SERP positions.
This means The top restaurant on page 2 for tacos is unlikely to be significantly worse than the one on page 1 due to the large amount of documents to analyze and return. Luckily I live in SoCal…. But that doesn’t mean Google does that.
Remember earlier when I did a Knowledge Graph API search to show how these things were rated? Let’s look at two of my favorite words: “Taco Score”. If you want to play along at home, go to this link and click Run in the lower right corner.
The following diagram shows the “Score Score” for the top 15 scores returned by the API for Tacos: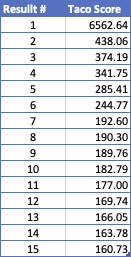
Apart from the fact that everything is caught up after the first result, the difference between positions 6 & 7 is the same as the difference between 7 & 15. Talk about insignificant differences from which you should not draw any conclusions …
If you need a graph to understand better, take a look at this long tail distribution curve
solutions
Okay Dan, you convinced me that our mental model of the SERPs is hijacking our brains in a negative way and our false precision is leading us astray, BUT WHAT DO I DO?
Well, glad you asked, random internet stranger, as I have a few concepts and tools that I hope will help you overcome this cognitive blocker.
Systems theory

The algorithm
To overcome false precision, I personally recommend taking a “systems theory” approach and trying it out Thinking in systems by Donella Meadows (old version available for free Here).
This is important because systems theory basically says that complex systems like Google Search are true black boxes that not even the people who work on the systems themselves know how they work. To be honest, this can only be seen in the face, though Google’s systems no longer used rel = prev and rel = next and it took them a couple of years to notice them.
The people who work on google search don’t know how it works to predict search results, it’s too complex a system. So we should stop using all this false precision. It looks IMHO stupid, not clever.

A google search engineer who works hard
Assume uncertainty
All of you, I hate teaching you this, but the search results are in no way predictable based on SEO research and the suggestion of a strategy and tactic as a result.

SEO math
We attribute a precise meaning to the unrecognizable in order to better help our fragile human brain to cope with the fear / fear of the unknown. The unknown / insecurity of these complex systems is baked into the cake. Just take into account the constant, overwhelming pace of Google Algo updates. They are constantly working to essentially change their systems substantially every month.
By the time you finish doing some real research to understand how much an update has changed to how the system works, you will have changed it a few times already. Therefore update / algo-chasing makes no sense to me. We work in an insecure, unrecognizable, complex system and to accept that means to forego false precision.
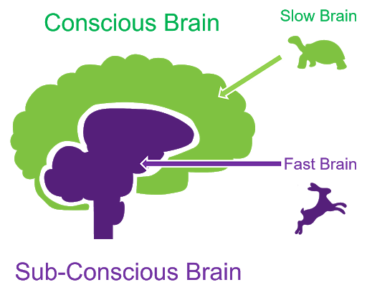
Think fast / think slowly
This is a concept of mind and behavioral economics developed by Nobel Prize-winning economist Daniel Kahnamen.
The human brain is insane
What this has to do with cognitive bias issues is that this Biases often arise from “quick thinking” or system 1 thinking. I am not going to delve too deep into or explain the difference between these two. Instead Daniel Kahnnames explains it himself here as well as a Explanation post here.
Just to illustrate how important I think this concept is to both SEO and leadership and decision making; I ask people in interviews “What’s your superpower?” And one of the most incredible SEOs I’ve ever worked with (Aimee Sanford!) Replied with “slow thinking” and that’s it.
Takeaways
I honestly think SEO is pretty straightforward and gets too complicated by the fact that our discipline is just overcrowded with marketing-marketing-marketers. When it comes to analyzing a core algorithm update out of context and / or making sweeping statements about what and how Google is behaving, then you should know that this is full of false precision.
We cannot even meaningfully discuss the distance between individual search positions, let alone how Internet scale systems work. When you internalize all of this false precision, it creates cognitive biases in your thinking that affect your performance. You will do worse on SEO.
Now all we have to do is tap into our slow thinking, overcome our cognitive bias, stop using false precision, and develop a new mental model. Easy right?